Data Integrity Matters | Limiting Access to Tools That Could Be Used to Manipulate Data (Part 1)

Data integrity controls have evolved – but have they gone too far?
As controls for data integrity have evolved, so too have expectations of the technical controls in software moved into a completely different kind of quandary.
Since the 1980s, we’ve had some basic expectations:
- Analysts in laboratories should not be able to delete data (to meet the data integrity principles of complete, enduring and available data).
- Analysts should have individual and non-shared user accounts (to ensure data is attributable).
- Computer systems – specifically new ones rather than legacy applications – should be equipped with unalterable audit trails that don’t rely on human recording of actions.
For these kinds of controls, removing the ability for individual users to either delete data or to disable audit trails (via user permissions or privileges) is expected to be both implemented and validated as effective.
As Quality Units get nervous about how analysts are using tools to falsify data, is the “0% risk approach” – removing access to any advanced functionality – the right solution?
However, in today’s environment, other tools have come under suspicion. In the chromatography world these tools may include peak integration methodologies and identification tools, as well as the ability to change/correct sample metadata.
Are these also tools that should not be accessible by an analyst?

The risks in modifying sample metadata
Let’s first consider the last tool mentioned and use the example of an entered Sample Weight. In an ideal world, critical values such as Sample Weight would be automatically entered by directly reading values from a balance. This requires automated integration between the instrument and the laboratory application such as a spreadsheet, the chromatography data software (CDS), an electronic laboratory notebook or LIMS, or automated integration between the lab-wide dedicated balance software and these other applications, which are seen as “consumers” of the Sample Weight information. Even in this idealized world, errors may occur; for example, the weight may be transferred to the incorrect sample entry and such mistakes need to be corrected.
Typically, this value is not automatically recorded and relies on the analyst to record the Sample Weight and manually transfer or type it into the application that will use that value in calculations. Here, there are even more opportunities for error – and they create more demand for the ability to correct that value. Therefore, audit trails that capture corrections of this kind of data should be in place – audit trails that automatically capture the identity, time, and actual correction (before and after) values, as well as requesting that the user records why that value needed to be changed.
Should the tool to make such corrections to sample metadata be taken out of the hands of analysts?
I believe only lab management can determine that. Here are some of the conflicting positions that can arise:
- The Quality Unit may argue, “If altering the Sample Weight could be used to manipulate data (such that a failing result might be falsely changed to a passing result), we can’t accept that risk. Don’t allow analysts to change sample weights ever, only managers can do that.”
- The Laboratory manager may have the view that the analytical staff should be trained to spot an incorrect entry during the peer review cycle and direct the original analyst to correct the mistake, before results are recalculated and reviewed.
- The Analytical staff may voice an opinion that “If nobody trusts me to do the right thing when an incorrect sample weight is populated, then let the Quality Unit review every run, spot any errors, and make the changes themselves.”
- A perfectionist among any of those roles might also say, “If the right Sample Weight was not entered before the test was run/calculated, then I prefer that the entire test is started again, with the correct data entry being reviewed before any test data is generated.”
Periodic review of audit trails relating to Sample Weight changes may offer more insight into why errors are being made that need to be corrected. Consider these three cases:
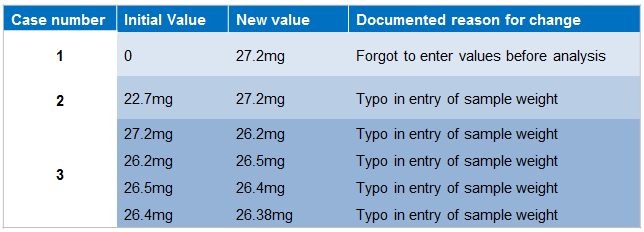
In the three cases shown in figure 1, the true situation may be indicative of a very different scenario.
- Cases 1 and 2 should be easily verified by looking at the original recording of the data from the balance.
- In Case 3, asking the analyst for evidence of the original weighing data should be done immediately, since it is likely to support only the original documented entry, with no evidence being available for any other recorded value.
What’s also clear here is that the “documented reason for change” has been falsely entered or the analyst has a true typing inability. Perhaps a sophisticated futuristic “mindreading application” may have recorded what the analyst was really thinking?
But what if changes are outright prohibited?
Prohibiting use of an editing tool for correcting sample weights may be the immediate reaction of a severely risk-adverse Quality Department. In this blog, I have clearly indicated how such a tool might be used to falsify results. Maybe something similar has been noted in an internal or external audit. But I’ve also shown above how an editing tool could be used responsibly – to correct actual errors in sample weight recording, either typographical errors or simple omissions.
It’s also obvious that the kind of falsification I showed in Case 3 ought to be easily uncovered though the data review process by reviewers trained to discern the correct use of this editing tool from deliberate falsification. The tool used to uncover this falsification is, in this case, the audit trail, and the false reasons for change – but it might equally be observable in the actual data results.
- Is it normal to use two decimal places?
- Does the method demand to weigh out between 27 and 30 mg?
- Does the final result calculated only just pass the specification? Could it be called borderline?
- Has the data been calculated multiple times, with each different weight? Would a spread sheet even indicate that?
The analysts involved in any instance such as Case 3 should be reprimanded and retrained in the correct use of that tool – maybe having their rights temporarily removed – but consider that a smarter resolution is to have their work more highly reviewed until their trustworthiness is restored.
Simply prohibiting or banning the use of edit tools for all staff is pointless and puts extra pressure on analysts, reviewers, and also whomever becomes “the only trusted person” allowed to correct such typing errors. But the wider data review process and the correct use of tools used should also be examined.
If such a case was happening in your laboratory, even if it was captured clearly in the audit trail, would your review processes be in sufficient detail to spot it before product was released?
Would your periodic review processes observe a trend if such editing tools were being used for deliberate data manipulation?
In all areas of life, machines, tools, or software may be used for the greater good or to accomplish acts of falsification or crimes, depending entirely on the training and motivation of the person wielding them. Think of guns, deadly infectious diseases, and even, today, motor vehicles. It’s not the tool alone that can be blamed for the crime, but the intent (or carelessness) of the person behind them.
In my next blog I will extend this idea into chromatographic peak integration.
Read more articles in Heather Longden’s blog series, Data Integrity Matters.
Related posts

Fostering a Supportive Community for Veterans
I am honored and privileged to be part of the community of veterans at Waters that fosters an opportunity to connect, share our experiences and support one another.

The Jim Waters Society Inductees Reflect Inventive Achievement
Four new Jim Waters Society inductees represent Waters’ top scientists and engineers for remarkable achievements.

Veterans Bring Leadership to the Waters Team
At Waters, we strive to unite and celebrate our diverse employee population. To this end, we have established Employee Circles, which create safe spaces where employees can share their experiences and learn from each other. Just before the pandemic, we launched the Veterans Circle—an employee resource group designed for and composed of Waters veterans and…
Popular Topics
ACQUITY QDa (16) bioanalysis (11) biologics (14) biopharma (26) biopharmaceutical (36) biosimilars (11) biotherapeutics (16) case study (16) chromatography (14) data integrity (21) food analysis (12) HPLC (15) LC-MS (21) liquid chromatography (LC) (19) mass detection (15) mass spectrometry (MS) (54) method development (13) STEM (12)